
起因是最近做一道文件包含的ctf题目时,卡了很久,最后才发现是对正则表达式的理解有问题导致,害,太菜了,最后反思了一下还是没有好好学习正则表达式(尤其是没有系统的进行学习),于是决定系统的学习一下正则表达式。
本次学习使用的学习资料为《精通正则表达式(第三版)》。内容主要为正则表达式基础和本人比较常遇到PHP环境下的正则表达式。
正则表达式基础
正则表达式由两种字符构成,元字符和文字,元字符为高级应用提供了丰富而且描述力极强。
行的起始和结束
^ 表示一行的开始
$ 表示一行的结束
^aa 匹配以aa开头的行
^$ 行开头接行末尾
^aa$ 一行内容为aa的行
字符组
匹配若干字符之一
同样的字符在字符组内和组外含义不同
连字符
‘-’连字符,表示一个范围(仅在字符组内部且不在开头连字符才是元字符)
例如:
<H[1-6]>与<H[123456]>是相同的
多重范围同样的允许的
例如:
[0-9A-Za-z]
排除型字符组
^表示排除,后面表示不希望匹配的字符
例如:
[^1-6] 匹配除了1到6以外的任何字符
用点号匹配任意字符
元字符.是用来匹配任意字符的字符组的简便写法,注意仅在字符组外为元字符
例如:
11.11
可以匹配11-11,11.11,11/11等
多选结构
‘|’或,简单易懂就是匹配表达式中的一个表达式
例如:
c(a|e)t 即可匹配cat也可以匹配cet
表达式前加上(?i)可以忽视大小写
单词分界线
< 用于匹配单词的开始位置
> 用于匹配单词的结束位置
可以想象成单词版本的^和$
两者可以一起使用用于匹配单词也可以只使用一个用于匹配某个字符串开始或结束的单词
\b 用于字符串开始或结尾进行匹配
m/\bjack/ 可匹配jack开头的所有字符串
m/jack\b/ 可匹配jack结尾的所有字符串
m/\bjack\b/ 只能匹配jack
可选项元素
?表示可选项
例如
jkk? 可以匹配jk和jkk
+表示之前邻接的元素出现一次或多次
例如
jk+ 可以匹配jkkkkkkkk、jk、jkkkk
*则是匹配任意次数,包括0次
jk* 可以匹配j、jk、jkkkkkk

贪婪:指尽可能的匹配出最长的内容
非贪婪:匹配出最短的内容
而*和+都是贪婪的,它们都会尽可能多的匹配文字。
只要在它们的后面加上一个?就可以实现非贪婪即最小匹配
例如:
<..>head<..>
/<.*>/ 匹配结果为<..>head<..>
/<.*?>/ 匹配结果为<..>
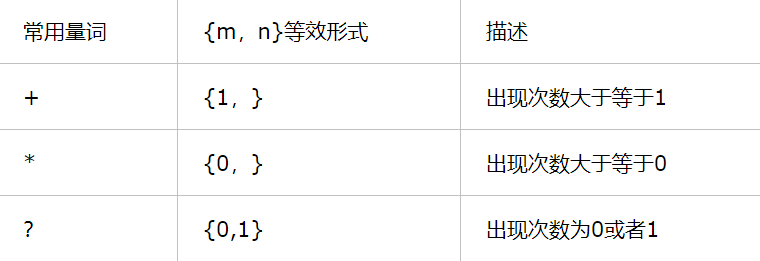
区间量词
{min,max}
上述三个元符号可以等价于以下量词
括号以及反向引用
括号除了将若干字符组合为一个单元,还有一个作用就是可以记录它们包含的子表达式匹配的文本。
\1匹配第一个括号内匹配的内容,\2匹配第二个括号匹配的内容,如此类推
例如:
<([A-Za-z]+) +\1> 匹配两个连续重复的单词
非捕获型括号
(?:)表示这个括号只进行分组而不捕获,即也不会影响捕获计数,即仅用于分组的括号
命名捕获
在python和php中,可以对捕获内容进行命名,语法相同,都是(?P
例如:
\b(?P\d\d\d)
转义
如果需要匹配的某个字符本身就是元字符,应该如何处理呢?
例如.本身就是元字符,在我们需要匹配一个网址时,我们可以这样写
www.baidu.com
或者匹配一个括号包含字符
([a-zA-Z]+)
主要流派的正则表达式的部分简记法
\s 匹配所有空白字符
\n 换行符
\r 回车符
\t 制表符
\S 除’\s’外的所有内容
\w 等价于[a-zA-Z0-9]
\W 除’\w’外的任何字符
\d 等价于[0-9],即数字
\D 除’\d’外的任何字符
/i修饰符表示此测试区不区分大小写,注意:虽然写法是’/i’,但其实“i”只是跟在表示结尾的斜线之后
m/../ 匹配
s/../../ 匹配并替换
环视结构
顺序环视
用(?=…)来表示
例如
(?=\d),表示如果当前位置右边的字符是数字则匹配成功
逆序环视
用(?<=….)表示
例如(?<=\d),表示如果当前位置左边有一位数字则匹配成功(即紧跟在数字后面的位置)
即逆序的查看(从右向左)文本进行匹配
否定顺序环视
(?!……) 不能匹配右侧的文本,即位置右侧不能是指定的文本
否定逆序环视
(?<!…)同上,只是改为不能匹配左侧的文本
环视不会“占用”字符
理解比较困难,这里直接使用实例
文本如下
hello Miss Alice.
下面用’‘包裹匹配的内容来表示匹配的内容
Miss 匹配 hello ‘Miss’ Alice
(?=Miss) 匹配 hello ‘‘Miss Alice
即Miss前面的位置,因为符合右边邻接Miss(即在Miss的前面)
(?=Miss)Mis 匹配hello ‘Mis’s Alice
(?=Miss)Mis 等价于 Mis(?=s)
s/../../g 全局替换
/m 多行查找(导致题目卡住的罪魁祸首~)
m 主要影响 ^、$。
若不指定 m,则:^ 只在字符串的最开头,$ 只在字符串的最结尾。即:匹配整个串的开始和结束
若指定 m,则:^ 在字符串每一行的开头,$ 在字符串每一行的结尾。即:匹配每一行的开始和结束
注意:在不同流派不同语言中正则表达式的格式存在细微区别
进制转义
8进制转义
\num
转义为ASCII中数字所代表的字符
16进制/Unicode转义
\xnum \x(num) \unum \Unum
控制字符
\cchar用于匹配小于32的控制字符(有些支持匹配更大的值)
\x
同时\x在php中被视为\P{M}|p{M}*的缩略表示,也可以看作点号的扩展
\x与点号的区别
1.\x能够匹配结尾的组合字符之外
-
\x能够匹配换行符和其他在Unicode行终结符
-
点号通配模式下的点号无论什么情况下都能匹配任何字符,而\x不能匹配以组合字符开头的字符
关于基本字符和组合字符可以自行搜索Unicode体系了解
Unicode的字符性质
Unicode不仅仅是一套字符映射规则,同时Unicode标准还定义了每一个字符的性质,例如“这个字符是标记字符(mark),它必须和其他字符一起使用”、“ 这个字符是小写字符”
等。
属性
不同的正则表达式系统对于这些属性的支持也不同,但是许多支持Unicode的程序能够通过\p(quality)并支持其中的一部分
\Pxx则匹配不具有对应属性的字符(等价于[^\p{xx}]
基本的Unicode属性分类如下
\p{L} \p{letter}字母
\p{M} \p{Mark}不能单独出现,必须和其他基本字符一起出现(例如:重音符号)的字符
\p{Z} \p{Separator}用于表示分隔,但本身不可见的字符
\p{S} \p{Symbol}各种图形符号和字母符号
\p{N} \p{Number}任何数字
\p{P} \p{Punctuation}标点字符
\p{C} \p{Other}匹配其他任何字符(很少用于正常字符)
注意:在部分系统中单字母属性可能不需要花括号(例如:\pL而不是\p{L}
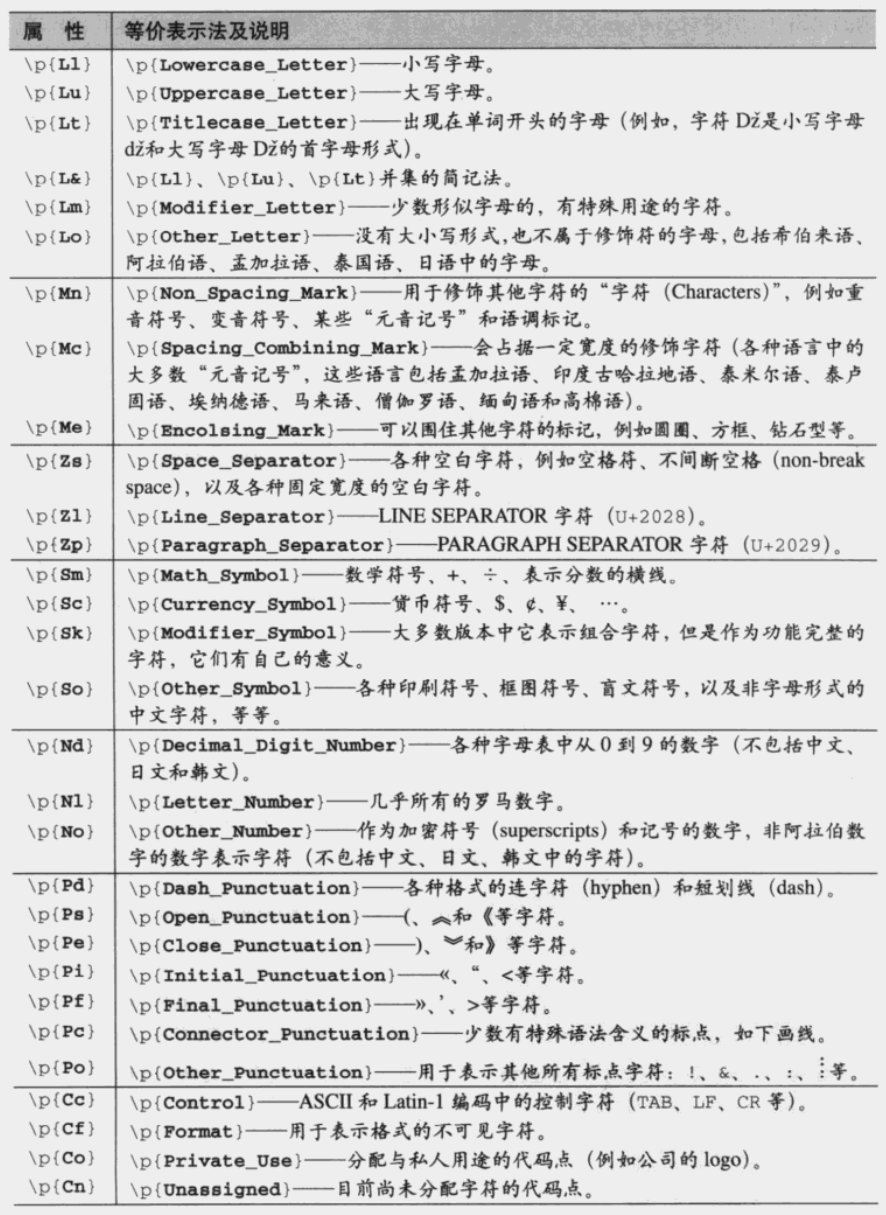
同时每个属性又包含若干的子属性,子属性还可以以某些实现方式支持的特殊形式实现复合
例如:\p{L&}等价于[\p{Lu}\p{Ll}\p{Lt}]
基本子属性如下:
字母表
部分系统能够按照字母表的名字以\p{…}的格式进行匹配,例如\p{Hebrew}匹配希伯来文独有的字符(不包含在其他书写系统中也常见的字符例如逗号)
部分字母表是基于语言的如泰国语,切罗基语等,
有的则包含多种语言,如拉丁文,有些语言包甚至包含多种字母表,例如日语的字符就有部分来自汉语、拉丁语等。具体请查看对应的文档。
注意:字母表只包含独属于(严格来说应该是几乎独属于,例如上文提到的日语),而不是特定书写系统的所有字符。而常见的字符则是通属于叫IsCommon的字符表,使用{IsCommon}来进行匹配。
扩展:还有一个伪字符表Inherited它包括从其所属的字符表中的基本字符继承而来的组合字符。
区块
区块类似但小于字母表(或者说是低配版的字母表),区块表示Unicode字符映射表中一定范围内的代码点。
例如Tibetan区块表示的是从U+0F00到U+0FFF的256个代码点。其中的字符可以用\p{InTibetan}来匹配.
为什么是低配版的字母表的原因如下:
1.区块可能包含没有赋值的代码点,例如在Tibetan区块中就有25%的代码点没有分配
2.并不像字母表那样,所有看上去和区块内的字符相关的字符都在区块内的
3.区块内也常常包含和区块不相干的字符,例如人民币符号¥在Latin_1_Supplement区块
4.区块是相互交叉的,即某个字母表的字符可能同时被包含于多个区块。例如希腊字母同时出现在Greek和Greek_Extended 区块中
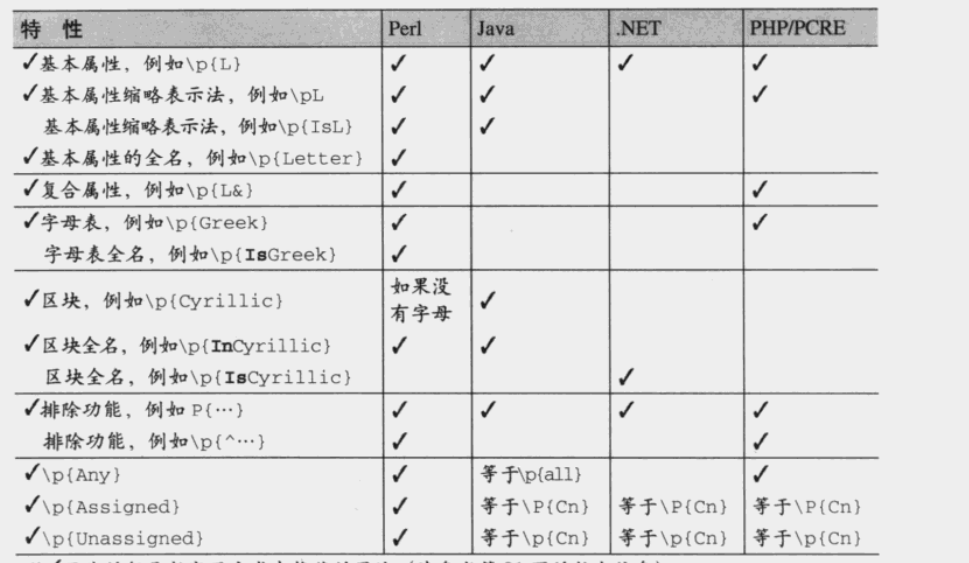
但是对于区块的支持比字母表更加普遍
比较常见的系统支持如下:
字符组运算
减号(-)
直接用实例说明
例如
[[a-z]-[aeiou]]
匹配的字符就是[a-z]能够匹配字符的减去[aeiou]能够匹配的字符
也即除了元音字母以外的字母
[\p{P}-[\p{Ps}\p{Pe}] ]
匹配\p{Ps}中除了[\p{Ps}\p{Pe}]外的字符
即匹配除了{和]之类成对的符号以外的所有标点符号。
OR
这个或上文有所提及的‘|“不同这里千万不要弄混了,在字符组中OR更像是一种简记法,用于以字符组的方式来先字符组中添加字符,更多时候用于排除型字符组中。
例如[abcxyz]等价于[ [abc] [xyz] ]、[ [abc]xyz]等等
&&
AND对两个集合进行与运算
例如[\p{InThai}&&\P{Cn}]
对\p{InThai}和\P{Cn}进行交运算
注意第二个P是大写即匹配不具有此属性的字符
也即\P{Cn}等价于[^\p{Cn}]
锚点及其他”零长度断言“
锚点及其他”零长度断言“并不匹配文本内容,而是寻找文本中的位置。
具体可参考下表
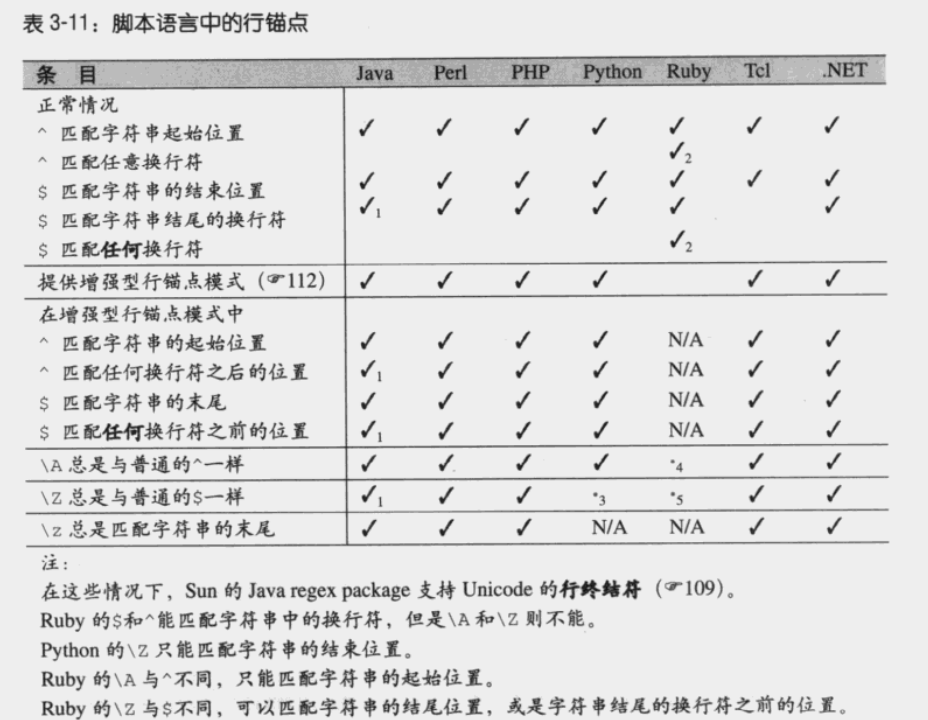
\G 用于匹配起始位置(或者是上一次匹配的结束位置)
模式修饰符(?modifier)
常见的模式修饰符字母

作用范围
(?:(?i)very)可化简为:
(?i:…..)表示在括号内有效
注意:python支持第一种即(?i)格式
但是不支持(?i:…)格式
注释(?#…)和#…
很少用到和见到,了解一下就ok了
固化分组 (?>…)
一旦括号内的子表达式匹配之后,匹配的内容就固定下来无法修改,并且在接下来的匹配过程中不会变化,除非整个固化分组的括号都被弃用。
例如:
文本为hello!
.*!是可以进行匹配的
而(?>.*)! 是无法被匹配的
因为在固化分组中hello!已经被.*所匹配且无法再被改变,所以没有!来匹配后面的那个!了
文字文本范围:\Q…\E
消除\E以外所有元字符的特殊含义,如果没有\E则一直作用到正则表达式末端。
即在\Q到\E的范围内,所有字符都被当做文本,元字符也不需要在前面加上\来说明用作字符了
忽略优先量词:*? , +? , ?? , {num,num}?
如果不确定是否要匹配,忽略优先量词会选择"不匹配"的状态,再尝试表达式中之后的元素,如果尝试失败,再回溯,选择之前保存的"匹配"的状态。
对[\s\S]来说,把**改为*?就是使用了忽略优先量词,?限定的元素出现次数范围与完全一样,都表示"可能出现,也可能不出现,出现次数没有上限"。区别在于,在实际匹配过程中,遇到[\s\S]能匹配的字符,先尝试"忽略",如果后面的元素不能匹配,再尝试"匹配",就如名字一样优先忽略出现的匹配结果
注意忽略优先量词和匹配优先量词本身在匹配次数上是没有区别的,例如和?的区间还都是[0,∞],区别在于,忽略优先量词会优先选择"忽略",而匹配优先量词会优先选择"匹配"。
占有优先量词:*+ , ++ , ?+ , (num,num)+
占有优先量词类似于普通的匹配优先量词,不过他们一旦匹配某些内容就不会”交还“,类似于固化分组
PHP环境下的正则
下面主要讨论的是preg引擎下提供的函数
注意点
preg引擎的一些说明
1.\b在字符组内部才表示退格符,在其他场合\b表示单词分界符
\0匹配空字节
2.单词分界符和字符简记法,例如\w,\s只对ASCII字符起作用(即使是在UTF-8模式下),如果要处理Unicode字符,可以用\pL代替\w,
\pN代替\d, \pZ代替\s
3.在PHP里,Unicode的字母表不需要类似于’Is’或者’ In’这样的前缀,而且属性不支持长名称,例如只能写作\pL,不支持\p{Letter}
PHP支持**\p{L&}**(等价于[\p{Lu}\p{Ll}\p{Lt}])和\p{Any}(表示任意字符)
4.默认情况下preg的正则表达式是以字节为单位的,所以\C等价于(?s:.),不过如果使用了修饰符u,preg就会自动变为以UTF-8字母为单位,即一个字符最多可能6个字节组成。但是\C仍匹配单个字节
5.\z和\Z都可以匹配字符串的末尾,\Z同样能够匹配最好的换行符
而$(匹配行末)的意义则会随着模式修饰符变化(m和D),
在没有设定任何修饰符时$等价于\Z
如果使用了m,则它可以匹配内嵌的换行符(那道题的解题关键)
如果使用了模式修饰符D,它能够匹配\z(只有在字符串的结尾)
如果同时设置了m和D则视为m
6.逆序环视结构使用的子表达式只能匹配固定长度的文本,除非顶层多选分支容许不同的固定长度
7.模式修饰符x(自由格式和注释)只能识别ASCII的空白字符,不能识别Unicode中的空白字符。
分隔符
preg要求正则表达式两侧必须要有分隔符,常见的做法是把斜线作为分隔符(注意我们可以使用除字母、数字、反斜线和空白字符外的任意ASCII字符做风格符),常见的是一对斜线,也有使用!和#作为分隔符的
PHP特有的修饰符
除四种标准修饰符里的模式修饰符外(i、s、m、x)
修饰符e只用于preg_replace,具体可以看函数preg_replace部分
模式修饰符u
以utf-8编码处理正则表达式和目标字符串,此模式不会修改数据,只是更改处理数据的方式,在utf-8编码中,非ASCII字符以多个字节来储存,使用u修饰符能够确保多个字节会作为单个字符来处理。
模式修饰符X
启动PCRE的额外功能,目前它只有一个效果,如果出现了无法识别的反斜线,就报告错误。例如,默认情况下,\k在PCRE中没有特殊意义,正常情况下会被看作k,如果使用了模式修饰符X,就会报告’unrecognized character follows "
模式修饰符S
调用PCRE的研究(study)特性,预先分析正则表达式,在某些顺利情况下,在尝试匹配时速度会大大提升。
不常用的模式修饰符
模式修饰符A 把匹配锚定再第一次尝试的位置,就等于整个正则表达式以\G开头
模式修饰符D 会把每个$替换成\z,即$匹配字符串的末尾,而不是字符串之内的换行符
模式修饰符U交换元字符的匹配优先含义:和?交换,(完全不知道这个是拿来干什么的,感觉一点用都没有)
Preg函数
preg_match
preg_match(pattern,subject[,matches[,flags[,offset]]])
测试正则表达式能否在字符串中找到匹配,并提取数据
参数
pattern 分隔符包围起来的正则表达式,可能有修饰符
subjuct 需要进行搜索的目标字符串
matches 非必要,用来接受匹配数据
flags 非必要,此标志位会影响整个函数的行为,这里只容许出现一个标志位
offset 非必要,从0开始,表示开始匹配的位置
返回值
成功匹配返回true否则返回false
preg_match_all
preg_match_all(pattern,subject,matches[,flags[,offset]])
在字符串中提取数据
参数
pattern 分隔符包围起来的正则表达式,可能有修饰符
subjuct 需要进行搜索的目标字符串
matches 必要,用来接受匹配数据(和preg_match不同的地方)
flags 非必要,此标志位会影响整个函数的行为,这里只容许出现一个标志位
offset 非必要,从0开始,表示开始匹配的位置
返回值
preg_match_all返回匹配的次数
preg_match_all可以以两种方式在$all_matches中存放数据,由参数flag决定
flag:PREG_PATTERN_ORDER或是PREG_SET_ORDER来决定
默认的排列方式是PREG_PATTERN_ORDER
下面是书中的例子

而如果使用PREG_SET_ORDER则会返回下面这个数组
|
|
preg_replace
preg_replace(pattern,replacement,subject[,limit[,count]]}
在字符串的副本中替换匹配的文本
参数
pattern 分隔符包围起来的正则表达式,可能有修饰符
replacement replacement字符串,如果pattern是一个数组,则replacement是包含多个子符 串的数组,如果使用了模式修饰符e,则字符串会被当作php代码
subjuct 需要进行替换的目标字符串,也可以是数组
limit 非必要,是一个整数,表示替换发生的上限
count 非必要,用来保存实际进行的替换次数(只有php5提供)
返回值
当subject是单个字符时,则返回一个字符串(subject可能被修改后的副本)
当subject是数组时则返回数组
Pattern和replacement可以以(字符串、字符串) (数组,字符串) (字符串,数组)
如果使用了模式修饰符e,replacement字符串的捕获引用会按照特殊的规定来插值:插值中的引号(单引号和双引号)会转义。如果不这样处理,插入的数值中的引号会让PHP代码出错。
preg_replace_callback
preg_replace_callback(pattern,callback,subject[,limit[,count]])
对字符串中的每处匹配文本调用处理函数
参数
pattern 分隔符包围起来的正则表达式,可能有修饰符
callback PHP回调函数,每次匹配成功,就执行它,生成replacement字符串
subjuct 需要进行替换的目标字符串,也可以是数组
limit 非必要,是一个整数,表示替换发生的上限
count 非必要,用来保存实际进行的替换次数(只有php5提供)
返回值
当subject是单个字符时,则返回一个字符串(subject可能被修改后的副本)
当subject是数组时则返回数组
preg_split
preg_split(pattern,subject[,limit,[flags]])
将字符串切分为子串数组
参数
pattern 分隔符包围起来的正则表达式,可能有修饰符
subjuct 需要进行分割的目标字符串
limit 非必要,是一个整数,表示切分之后元素的上限
flags 非必要,此标志位会影响整个函数的行为,以下三种可以随意组合
PREG_SPLIT_NO_EMPLY
PREG_SPLIT_DELIM_CAPTURE
PREG_SPLIT_OFFSET_CAPTURE
返回值
返回一个字符串数组
flag参数
三个标志位都会影响函数的功能,它们可以单独使用,也可以用or连接
PREG_SPLIT_OFFSET_CAPTURE
类似于preg_match_all中的PREG_OFFSET_CAPTURE,这个标志位会修改结果数组,把每个元素变为包含两个元素的数组
PREG_SPLIT_NO_EMPLY
这个标志位设定后preg_split会忽略空字符串,不把它们放在返回数组中,也不计入limit的统计中。
PREG_SPLIT_DELIM_CAPTURE
这个标志位在结果中包含匹配的文本,以及进行此次切分的正则表达式的捕获括号匹配的文本,下面用例子说明
字符串如下,而且是用or和and来连接的
DLSR camera and Nikon D200 or Canon EOS 30D
在不使用PREG_SPLIT_DELIM_CAPTURE的情况下
|
|
结果是
|
|
分隔符内容被去掉了,但是如果使用了PREG_SPLIT_DELIM_CAPTURE呢
|
|
结果如下,即分隔符也被包括进去了
|
|
prep_grep
preg_grep(pattern,input[,flags])
选出数组中能(不能)由表达式匹配的元素
参数
pattern 分隔符包围起来的正则表达式,可能有修饰符
input 一个数组,如果它们的值能够匹配pattern,则其值会复制到返回的数组中。
flags 非必要,此标志位PREG_GREF_INVERT或者是0
返回值
一个数组,包含input中能够由pattern匹配的元素(如果使用了PREG_GREF_INVERT标志位,则包括不能匹配的元素)
preg_quote
preg_quote(input[,delimiter])
转义字符串中的正则表达式元字符
参数
input 希望以文字方式用作pattern参数的字符串
delimiter 非强制出现的参数,包含1个字符的字符串,表示希望用在pattern参数的分隔符
返回值
preg_quote返回一个字符串,它是input的副本,其中的正则表达式元字符进行了转义,如果指定了分隔符,则分隔符本身也会被转义。